“Perfect” is the enemy of “Good Enough”.
Taking Time to Smell the Roses
I haven’t made a new post in some time now. In between writing scripts for my experiments and LaTeX, I have little time to program for fun. Thankfully, my winter semester is over and the spring of 2022 seems to be delayed; I’m at a delightful intersection where no one expects anything from me and I can’t do much outside anyway. I’m sitting in my parents’ lawn, watching our cats, and I want to make something.
I don’t have the time to make something from scratch, but I do have one old project I wanted to remake: the Wikipedia Network Research Assistant. Two years ago, I wrote a version of this tool in Python when I first learned the language. I’m sure I made it suboptimally, I’d like to return to this well.
The Wikipedia Network Research Assistant (WNRA)
(Not to be confused with the Women’s National Rifle Association)
The premise here is simple:
- Ask the user for a term.
- Look up the Wikipedia article for that term.
- Using some heuristic, figure out a list of the most commonly related terms.
- Recursively figure out what terms are related to those terms (with a configurable depth and breadth of the search).
- Visualize the results.
I used the best libraries I could find for this kind of task: Wikipedia to scan the Wikipedia pages and NetworkX to visualize the results in a network plot. After about 90 lines of code, I was really happy with the results, presented below:
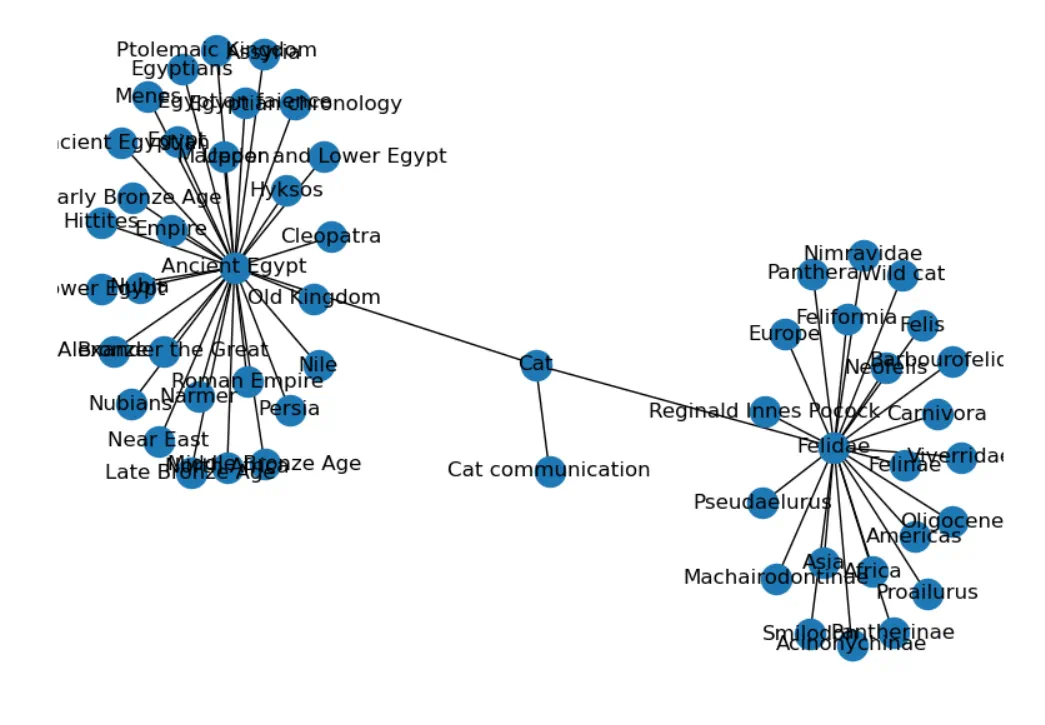
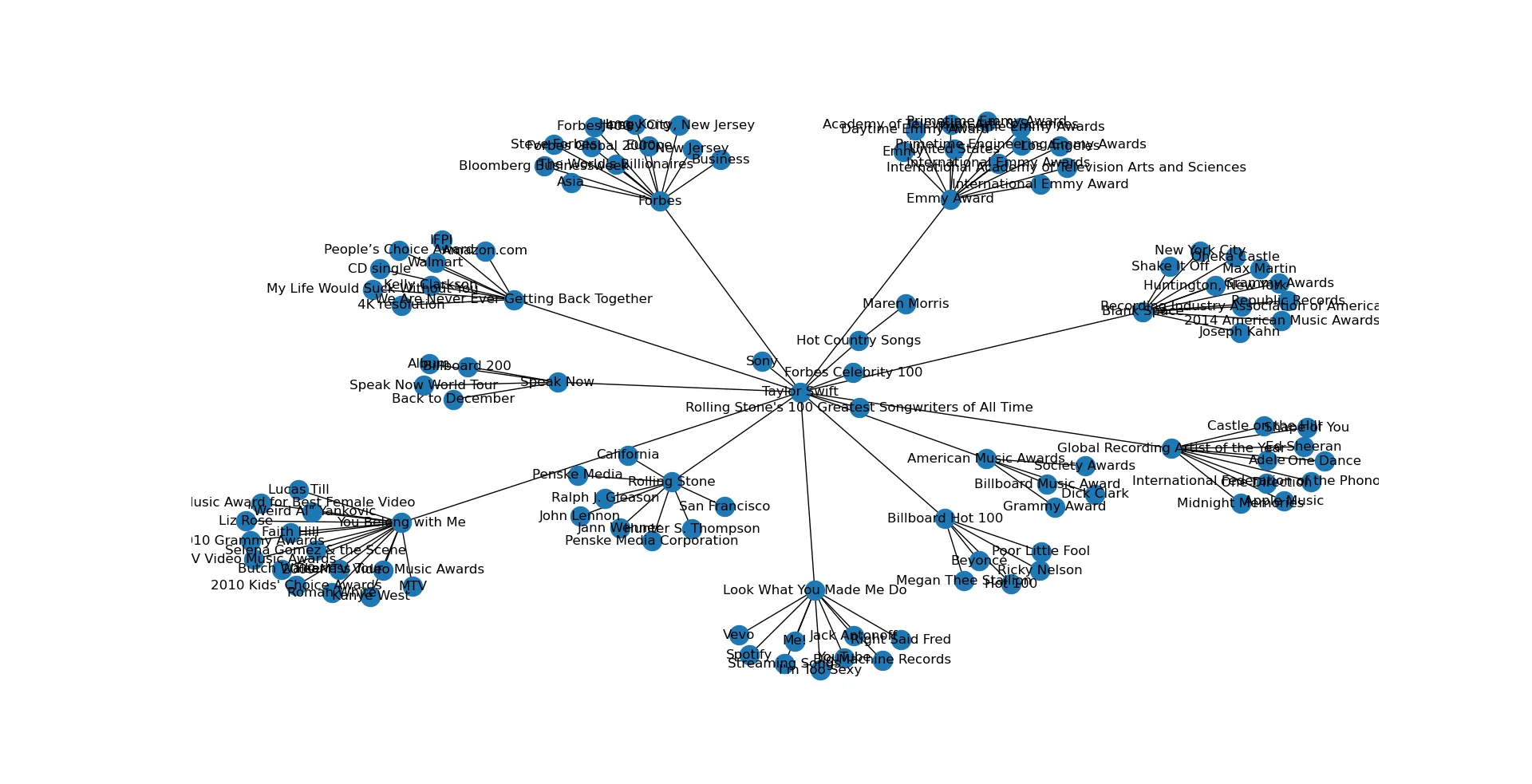

Thoughts on the Results
-
It’s unreadable (I didn’t care to look any deeper in the NetworkX library to make text a little more legible. The sun is setting, and it’s time to take my cats back inside.)
-
The way networks form is surprisingly pleasing to the eye, even though I didn’t spend any effort on this part. Shout-out to the developers of NetworkX.
-
I could apply this to other APIs: Elsevier, IEEE, and Google Scholar all seem to have some sort of API accessible through Python (even if they are not official).
-
Kanye West does not show up in Taylor Swift’s network. It seems he did not make her famous.
-
There’s no child nodes that connect to each other. Did I forget to program that in or is that somehow just how these results look?
-
There’s no visual indication here of whether there is a two-way connection between parent nodes and their children. In other words, there’s no way to know if a node is the child of its own children. In other words, is a node its own grandparent?
-
These results are extremely cherry-picked - most terms would throw errors for some reason (this seems to be a flaw with the Wikipedia API I’m using). I did find the more involved PyWikiApi, a minimalistic library for the core MediaWiki API when I started, but chose to ignore it for simplicity. This is on me.
-
It would be nice to embed more information. Things like:
a. Word count of article (relate it to the size of the node)
b. Date Article was created (transparency of the node)
c. Degrees of Separation from Initial Term (colour of node/edge)
d. Number of cross-references between articles (thickness of edge)
I will stop myself before I get too deep into potential improvements. That well would never dry.
On the Unreasonable Effectiveness of Python Libraries
It’s been said by a million people before me, but the code-density of Python is absurd. This project took an afternoon and less than 100 lines.
I fear not the codebase with 10k lines of C, I fear the codebase with 10k lines of Python.